MySQL 性能优化神器 Explain 使用分析 - 后台开发 - SegmentFault 思否
MySQL 性能优化神器 Explain 使用分析 - 后台开发 - SegmentFault 思否








最近回顾前几年写的Raft、etcd raft的实现文章,以及重新阅读Raft论文、etcd raft代码,发现之前有些理解不够准确、深刻,但是不打算在原文上做修正,于是写这篇补充的文章做一些另外角度的解释,以前的系列文章可以在下面的链接中找到,本文不打算过多重复原理性的内容:
概述
在开始展开讨论前,先介绍这个Raft论文中的示意图,我认为能理解这幅图才能对一致性算法有个全貌的了解:
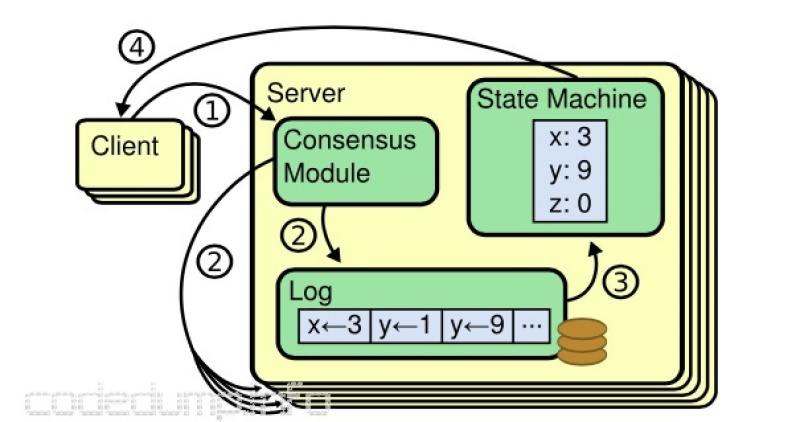
图中分为两种进程:
- server进程:server进程中运行着一致性算法模块、持久化保存的日志、以及按照日志提交的顺序来进行顺序操作的状态机。
- client进程:用于向server提交日志的进程。
需要说明的是,两种进程都用叠加的矩形来表示,意指系统中这两类进程不止一个。
一个日志要被正确的提交,图中划分了几步:
1、client进程提交数据到server进程,server进程将收到的日志数据灌入一致性模块。
2、一致性模块将日志写入本地WAL,然后同步给集群中其他server进程。
3、多个节点对某条日志达成一致之后,将修改本地的提交日志索引(commit index);落盘后的日志按照顺序灌入状态机,只要保证所有server进程上的日志顺序,那么最后状态机的状态肯定就是一致的了。
4、灌入状态机之后,server进程可以应答客户端。
所以,本质上,一个使用了一致性算法的库,划分了成了两个不同的模块:
- 一致性算法库,这里泛指Raft、Paxos、Zab等一致性协议。这类一致性算法库主要做如下的事情:
- 用户输入库中日志(log),由库根据各自的算法来检测日志的正确性,并且通知上层的应用层。
- 输入到库中的日志维护和管理,算法库中需要知道哪些日志提交、提交成功、以及上层的应用层已经applied过的。当发生错误的时候,某些日志还会进行回滚(rollback)操作。
- 日志的网络收发,这部分属于可选功能。有一些库,比如braft把这个事情也揽过来自己做了,优点是使用者不需要关注这部分功能,缺点是braft和它自带的网络库brpc耦合的很紧密,不可能拆开来使用;另一些raft实现,比如这里重点提到etcd raft实现,并不自己完成网络数据收发的工作,而是通知应用层,由应用层自己实现。
- 日志的持久化存储:这部分也属于可选功能。前面说过,一致性算法库中维护了未达成一致的日志缓冲区,达成一致的日志才通知应用层,因此在这里不同的算法库又有了分歧,braft也是自己完成了日志持久化的工作,etcd raft则是将这部分工作交给了应用层。
- 用户输入库中日志(log),由库根据各自的算法来检测日志的正确性,并且通知上层的应用层。
- 应用层:即工作在一致性算法之上的库使用者,这个就比上图中的“状态机”:只有达成一致并且落盘的数据才灌入应用层,只要保证灌入应用层的日志顺序一致那么最后的状态就是一致的。
总体来看,一个一致性算法库有以下必选和可选功能:
- 输入日志进行处理的算法(必选)。
- 日志的维护和管理(必选)。
- 日志(包括快照)数据的网络收发(可选)。
- 日志(包括快照)的持久化存储(可选)。
需要特别说明的是,即便是后面两个工作是可选的,但是可选还是必选的区别在于,这部分工作是一致性算法库自己完成,还是由算法库通知给上面的应用层去完成,并不代表这部分工作可以完全不做。
在下表中列列举了etcd raft和braft在这几个特性之间的区别:
| 功能 | etcd raft | braft |
|---|---|---|
| raft一致性算法 | 实现 | 实现 |
| 日志的维护和管理 | 实现 | 实现 |
| 日志数据的网络收发 | 交由应用层 | 自己实现 |
| 日志数据的持久化存储 | 交由应用层 | 自己实现 |
| 优缺点 | 松耦合,易于验证、测试;需要应用者做更多的事情 | 与其rpc库紧耦合,难拆分;应用层做的事情不多,易于用来做服务 |
两种实现各有自己的优缺点,braft类实现更适合提供一个需要集成raft的服务时,可以直接用来实现服务;etcd raft类的实现,由于与网络、存储层耦合不紧密,易于进行测试,更适合拿来做为库使用。
如果把前面的一致性算法的几个特性做一个抽象,我认为一致性算法库本质上就是一个“维护操作日志的算法库,只要大家都按照相同的顺序将日志灌入应用层”就好,其工作原理大体如下图:
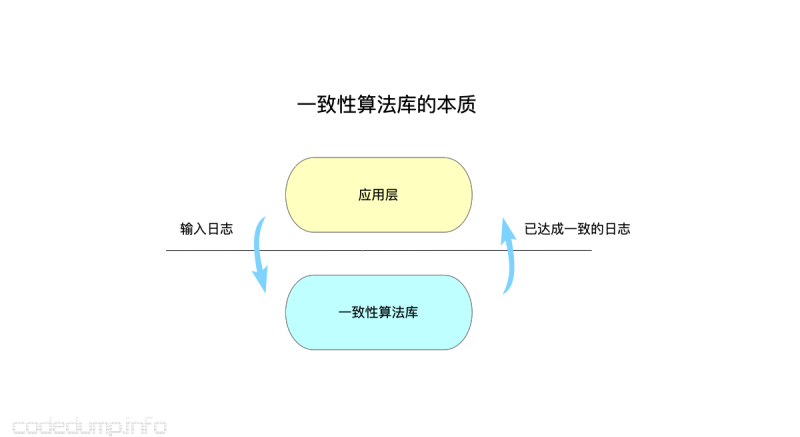
如果把问题抽象成这样的话,那么本质上,所谓的“一致性算法库”跟一个经常看到的tcp、kcp甚至是一个应用层的协议栈也就没有什么区别了:
- 大家都要维护一个数据区:只有确认过正确的,才会抛给上一层。以TCP协议算法来说,比如发送但未确认的数据由协议栈的缓冲区维护,如果超时还未等到对端的确认,将发起超时重传等,这些都是每种协议算法的具体细节,但是本质上这些协议都要维护一个未确认数据的缓冲区。一致性算法在数据的维护上会更复杂一些,一是参与确认的节点不止通信的C/S两端,需要集群中半数以上节点的确认;同时,在未确认之前日志需要首先落盘,在提交成功之后再抛给应用层。
- 只要保证所有参与的节点,都以相同的数据灌入日志给应用层,那么得到的结果将最终一致。
- 确认的流程是可以pipeline异步化的,提交日志的进程并不需要一直等待日志被提交成功,而是提交之后等待。不妨以下面的流程来做解释:
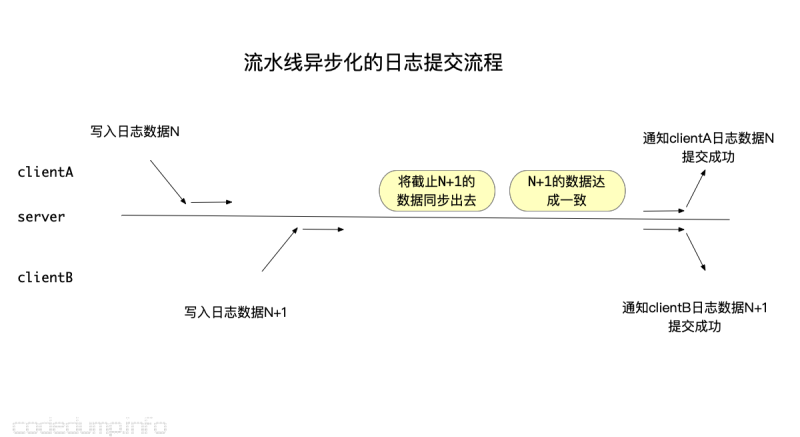
其中:
- clientA和clientB分别提交了两条日志数据,但是并没有阻塞等待日志提交成功,而是提交之后就继续别的操作了。
- server将两条日志数据同步出去,达成一致之后再分别通知两个client日志提交成功。
在这里,client上通知日志提交成功的机制可以有很多,以etcd来说,会给每个提交的日志对应一个channel,提交成功之后会通过这个channel进行通知,也会给这个日志加一个定时器,超过时间仍未收到通知则认为提交失败。
etcd raft的实现
有了上面对一致性算法库的大体了解,下面可以详细看看etcd raft的实现了。
概述
前面提到过,etcd raft库的实现中,并不自己实现网络数据收发、提交成功的数据持久化等工作,这些工作留给了应用层来自己实现,所以需要一个机制来通知应用层。etcd raft中将需要通知给应用层的数据封装在Ready结构体中,其中包括如下的成员:
| 成员名称 | 类型 | 作用 |
|---|---|---|
| SoftState | SoftState | 软状态,软状态易变且不需要保存在WAL日志中的状态数据,包括:集群leader、节点的当前状态 |
| HardState | HardState | 硬状态,与软状态相反,需要写入持久化存储中,包括:节点当前Term、Vote、Commit |
| ReadStates | []ReadStates | 用于读一致性的数据,后续会详细介绍 |
| Entries | []pb.Entry | 在向其他集群发送消息之前需要先写入持久化存储的日志数据 |
| Snapshot | pb.Snapshot | 需要写入持久化存储中的快照数据 |
| CommittedEntries | []pb.Entry | 需要输入到状态机中的数据,这些数据之前已经被保存到持久化存储中了 |
| Messages | []pb.Message | 需要发送出去的数据 |
有了数据,还需要raft线程与上面的应用层线程交互的机制,这部分封装在node结构体中。
node结构体实现Node接口,该接口用于表示Raft集群中的一个节点。在node结构体中,实现了以下几个核心的channel,由于与外界进行通信:
- propc chan pb.Message:用于本地提交日志数据的channel。
- recvc chan pb.Message:用于接收来自集群中其他节点日志数据的channel。
- readyc chan Ready:用于本地Raft库通知应用层哪些数据已经准备好了,因此应用层需要关注readyc这个channel才能获得从Raft线程中提交的数据。
去掉一些不太重要的接口,Node接口中有如下的核心函数:
- Tick():应用层每次tick时需要调用该函数,将会由这里驱动raft的一些操作比如选举等,至于tick的单位是多少由应用层自己决定,只要保证是恒定时间都会来调用一次就好了。
- Propose(ctx context.Context, data []byte) error:提议写入数据到日志中,可能会返回错误。
- Step(ctx context.Context, msg pb.Message) error:将消息msg灌入状态机。
- Ready() <-chan Ready:返回通知
Ready结构体变更的channel,应用层需要关注这个channel,当发生变更时将其中的数据进行操作。 - Advance():Advance函数是当使用者已经将上一次Ready数据处理之后,调用该函数告诉raft库可以进行下一步的操作。
在node结构体的实现中,无论是通过Propose函数还是Step函数提交到Raft算法库的消息,最终都是调用内部的step函数的。
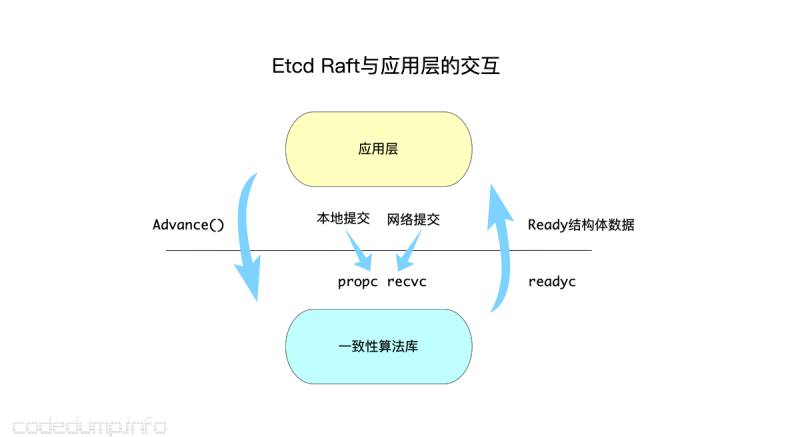
以上图来说明应用层与raft之间的交互流程,注意:etcd的实现中,raft是一个独立的线程,与应用层之间通过上面介绍的几个channel进行交互。
- 首先看最中间的部分,本地提交的数据通过
propcchannel通知raft线程,而应用层从外部网络接收到的日志数据通过recvc通知raft线程。但是不管是哪个channel,最终都是通过上面提到的step函数将日志数据灌入raft线程中。 - 最右边是raft线程通知应用线程有哪些日志数据已经确认提交完毕等(
Ready结构体中不限于确认提交数据,该类型数据在上面已经列举出来),应用层可以通过Ready数据来持久化数据等操作。 - 最左边表示应用层线程要通过
Advance函数通知raft线程自己已经持久化了某些数据,这时候可以推动raft线程库中的日志缓冲区的变更。
以一个简单的消息流程来继续解释上面的流程:
- 应用层收到索引为N的消息,此时通过
recvcchannel提交给Raft线程。 - Raft线程验证消息是正确的,于是需要广播给集群中的其他节点,此时会:
- 首先在Raft的日志缓冲区中保存下来这个消息,因为这个日志还未提交成功。
- 将日志消息放入
Ready结构体的Messages成员中,通知应用层,这样应用层就将该成员中的消息转发给集群中的其他节点。
- Raft线程继续获得从应用层下发下来的消息,当发现下发的消息中,索引为N的消息已经被集群中半数以上的节点确认过,此时就可以认为该消息能被持久化了,将日志消息放入
Ready结构体的CommittedEntries成员中,以通知应用层该消息可以被持久化了。 - 每次应用层持久化了某些消息之后,都会通过
Advance函数通知Raft线程,这样Raft线程可以将这部分已经被持久化的消息从消息缓冲区中删除,因为前面提到过消息缓冲区仅仅是用来保存还未持久化的消息的。
这个工作流程是pipeline化,即应用层某一次提交了索引为N的消息,并不需要一直等待该消息提交成功,而是可以返回继续做别的事情,当raft线程判断消息可以被提交时,再通过Ready结构体来通知应用层。
以上大体描述了etcd中,应用层线程与raft线程的交互流程,下面详细看看raft线程的实现。
Raft算法
raft算法中,有不同的角色存在:candidate、follower、leader,本质上Raft算法是输入日志数据进行处理,而每种角色对不同类型的日志数据需要有不同的处理。
所以,etcd raft的实现中,针对三种不同的角色,通过修改函数指针的方式在切换了不同角色时的处理,如下图所示:
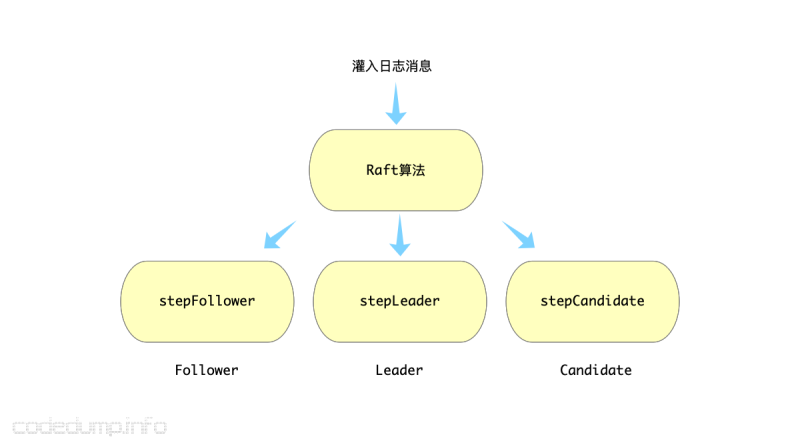
具体的算法细节,不打算在本文中展开,可以回头上上面给出来的几篇文章。
数据管理
数据管理分为以下几部分阐述:
- 未持久化数据缓冲区
- 持久化数据内存映像
- 数据的持久化
- 数据流动的全流程
- 节点进度的管理
下面一一展开。
未持久化数据缓冲区
前面提到过,Raft算法中还必须要做的是维护未确认数据的缓冲区数据,每当其中的一部分数据被确认,缓冲区的窗口随之发生移动,这就类似TCP协议算法中的滑动窗口。
etcd raft中,管理未确认数据放在了unstable结构体(log_unstable.go)中,其内部维护三个成员:
- snapshot *pb.Snapshot:保存还没有持久化的快照数据
- entries []pb.Entry:保存还未持久化的日志数据。
- offset uint64:保存快照和日志数组的分界线。
可以看到,未持久化数据分为两部分:一部分是快照数据snapshot,另一部分就是日志数据数组。两者不会同时存在,快照数据只会在启动时进行快照数据恢复时存在,当应用层使用快照数据进行恢复之后,raft切换为可以接收日志数据的状态,后续的日志数据都会写到entrise数组中了,而两者的分界线就是offset变量。
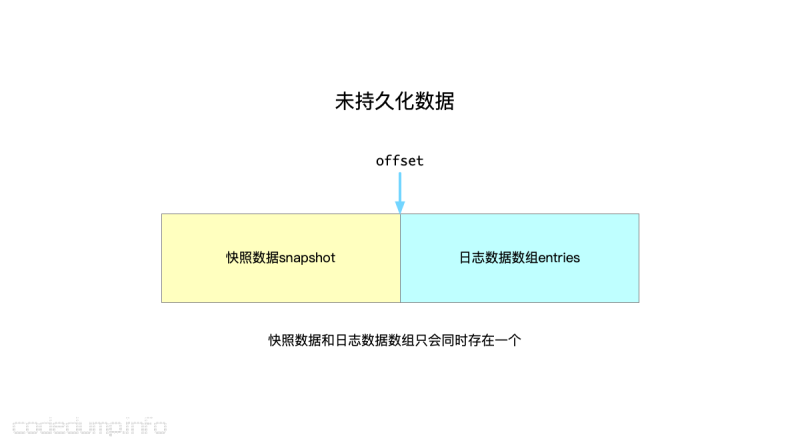
由于是”未持久化数据的缓冲区“,因此这其中的数据可能会发生回滚(rollback)现象,因此unstable结构体需要支持能回滚的操作,见函数truncateAndAppend:
func (u *unstable) truncateAndAppend(ents []pb.Entry) {
// 先拿到这些数据的第一个索引
after := ents[0].Index
switch {
case after == u.offset+uint64(len(u.entries)):
// 如果正好是紧接着当前数据的,就直接append
// after is the next index in the u.entries
// directly append
u.entries = append(u.entries, ents...)
case after <= u.offset:
u.logger.Infof("replace the unstable entries from index %d", after)
// The log is being truncated to before our current offset
// portion, so set the offset and replace the entries
// 如果比当前偏移量小,那用新的数据替换当前数据,需要同时更改offset和entries
u.offset = after
u.entries = ents
default:
// truncate to after and copy to u.entries
// then append
// 到了这里,说明 u.offset < after < u.offset+uint64(len(u.entries))
// 那么新的entries需要拼接而成
u.logger.Infof("truncate the unstable entries before index %d", after)
u.entries = append([]pb.Entry{}, u.slice(u.offset, after)...)
u.entries = append(u.entries, ents...)
}
}
函数中分为三种情况:
- 如果传入的日志数据,刚好跟当前数据紧挨着(after == u.offset+uint64(len(u.entries))),就可以直接进行append操作。
- 如果传入的日志数据的第一条数据索引不大于当前的offset(after <= u.offset),说明数据发生了回滚,直接用新的数据替换旧的数据。
- 其他情况,说明u.offset < after < u.offset+uint64(len(u.entries)),这是新的未持久化数据由这两部分数据各取其中一部分数据拼装而成。
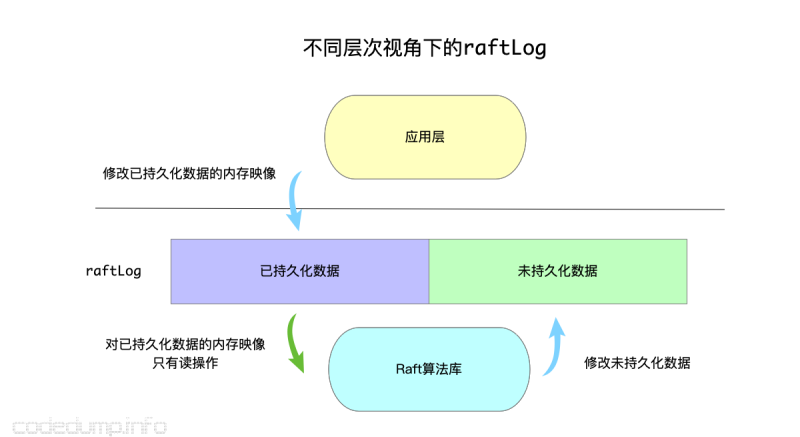
持久化数据内存映像
但是,仅仅有未持久化数据还不够,有时候有一些数据已经落盘,但是还需要进行查询、读取等操作。于是,etcd raft又提供了一个Storage接口,该接口有面对不同的组件有不同的行为:
- 对于Raft库,该接口仅仅只有读操作。(如下图中的黄色函数)
- 对于etcd 服务来说,还提供了写操作,包括:增加日志数据、生成快照、压缩数据。(如下图中的蓝色函数)
因此,这个接口及其默认实现MemoryStorage,呈现了稍微不太一样的行为,以致于我最开始没有完全理解:
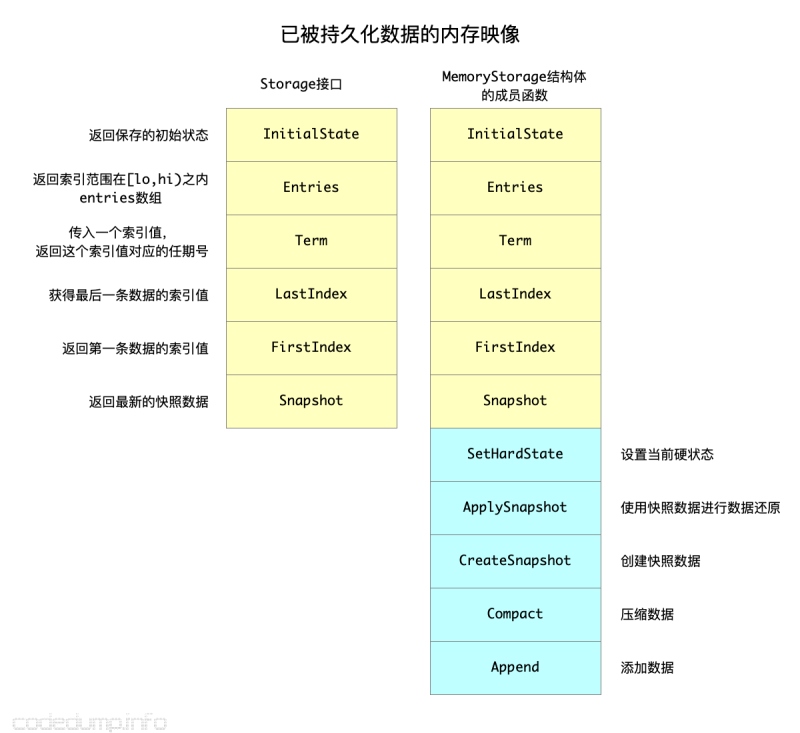
因为持久化数据的内存映像,提供给Raft库的仅仅只需要读操作,所以Storage接口就只有读操作,多出来的写操作只会在应用层中才会用到,因此这些写接口并没有放在公用的接口中。
了解了持久化和未持久化数据的表示之后,etcd raft库将两者统一到raftLog这个结构体中:
数据的持久化
以上解释两种缓冲区的作用,数据最终还是需要持久化到磁盘上的,那么,这个持久化数据的时机在哪里?
答案:当客户端提交数据时,etcd Raft库就通过Ready结构体的Entries成员通知应用层,将这些提交的数据进行持久化了。
有代码为证。
首先来看raft中如何生成Ready数据:
func newReady(r *raft, prevSoftSt *SoftState, prevHardSt pb.HardState) Ready {
rd := Ready{
// entries保存的是没有持久化的数据数组
Entries: r.raftLog.unstableEntries(),
// 保存committed但是还没有applied的数据数组
CommittedEntries: r.raftLog.nextEnts(),
// 保存待发送的消息
Messages: r.msgs,
}
// ...
}
可以看到,raft库中将未持久化数据塞到了Entries数组中,而已经达成一致可以提交的日志数据放入到CommittedEntries数组中。
以etcd代码中自带的raftexample目录中的例子代码来看应用层在收到Ready数据后的做法:
func (rc *raftNode) serveChannels() {
case rd := <-rc.node.Ready():
// 将HardState,entries写入持久化存储中
rc.wal.Save(rd.HardState, rd.Entries)
if !raft.IsEmptySnap(rd.Snapshot) {
// 如果快照数据不为空,也需要保存快照数据到持久化存储中
rc.saveSnap(rd.Snapshot)
rc.raftStorage.ApplySnapshot(rd.Snapshot)
rc.publishSnapshot(rd.Snapshot)
}
rc.raftStorage.Append(rd.Entries)
rc.transport.Send(rd.Messages)
if ok := rc.publishEntries(rc.entriesToApply(rd.CommittedEntries)); !ok {
rc.stop()
return
}
rc.maybeTriggerSnapshot()
rc.node.Advance()
// ....
}
其中:
- rc.wal.Save(rd.HardState, rd.Entries):将客户端提交数据的数据写入wal中。
- rc.raftStorage.Append(rd.Entries):这里的
raftStorage即前面提到的持久化数据缓冲区的Storage接口,由MemoryStorage接口实现,这一步将这些客户端提交的数据也写入持久化缓冲区的内部映像。 - rc.publishEntries(rc.entriesToApply(rd.CommittedEntries)):这个调用分为两步,第一步调用
entriesToApply是要从已达成一致的日志数据中过滤出真正可以进行apply的日志,因为里面的一些日志可能已经被应用层apply过,第二步将第一步过滤出来的日志数据通知给应用层。在raftexample这个示例代码中,最终这些已经达成一致的数据,会被遍历生成KV内存数据。
这里有一个问题:客户端提交过来的数据,还未达成集群内半数节点的一致,这时候就去做落盘操作,如果提交过程中发现出了问题,实际这条数据并不能最终达成一致,那么已落盘的数据怎么办?
在这里,etcd落盘客户端提交的数据时,是写入到WAL文件中的,后面发生了错误,如leader变成了follower时,日志需要进行了回滚操作等,也还是将那些正确的日志继续添加到WAL日志后面,服务如果重启,就是把这些日志按照顺序重放(replay)一遍,这里不可避免的会有一些冗余的操作,但是随着快照文件的产生,这个问题已经不大了。
其次,不论是前面提到的未持久化数据缓冲区,还是持久化数据缓冲区,在往缓冲区中添加日志的函数实现中,都会去判断日志是否发生了回滚,会将当前传入的日志按照正确的日志索引放到缓冲区合适的位置。未持久化数据缓冲区这部分操作在函数unstable.truncateAndAppend中,持久化数据缓冲区这部分操作在函数MemoryStorage.Append中,感兴趣的可以去看看具体的实现,在这里就不再展开了。
数据流动的全流程
以上解释了客户端提交的数据在两个缓冲区、持久化存储、以及最终达成一致之后给应用层的过程,下面以例子分别来解释客户端提交数据的流程以及快照数据恢复的流程。
客户端提交数据的流程
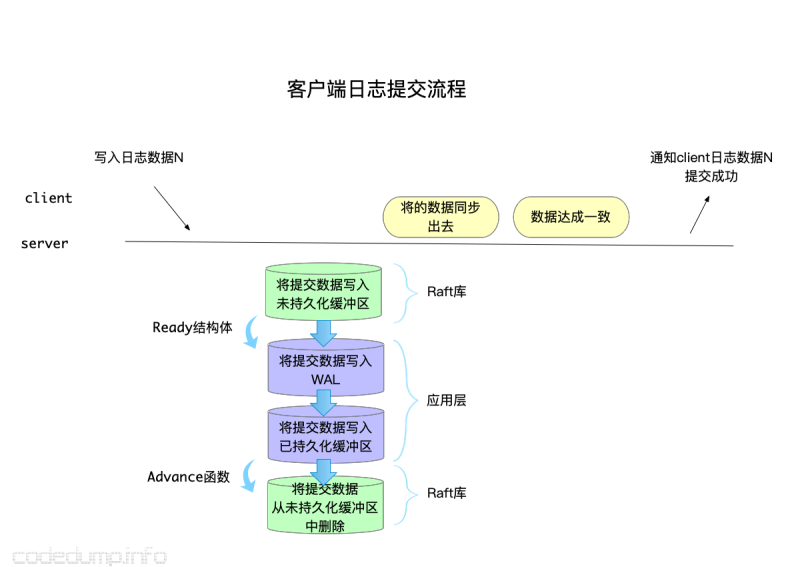
1、客户端提交数据给服务器。
2、接着看这条数据走过的”存储“路径:
1、首先,`raft`库会首先将日志数据写入`未持久化数据缓冲区`。
2、由于`未持久化数据缓冲区`中有新增的数据,会通过`Ready`结构体通知给应用层。
3、应用层收到`Ready`结构体之后,将其中的数据写入WAL持久化存储,然后更新这块数据到`已持久化数据缓冲区`。
4.1、持久化完毕后,应用层通过`Advance`接口通知`Raft`库这些数据已经持久化,于是raft库修改`未持久化数据缓冲区`将客户端刚提交的数据从这个缓冲区中删除。
4.2、持久化完毕之后,除了通知删除`未持久化数据缓冲区`,还讲数据通过网络同步给集群中其他节点。
3、集群中半数节点对该提交数据达成了一致,可以应答给客户端了。
启动时使用快照数据恢复流程
下面以例子来实际解释etcd raft中数据在未持久化缓存、wal日志、持久化数据内容映像中的流动:
1、节点N启动,加入到集群中,此时发现N上面没有数据,于是集群中的leader节点会首先通过rpc消息将快照数据发送给节点N。
2、节点N收到快照数据,首先会保存到未持久化数据缓存中。
3、Raft通过Ready结构体通知应用层有快照数据。
4、应用层(也就是etcdserver)将快照数据写入wal持久化存储中,这一步可以理解为将快照数据落盘。
5、落盘之后,调用MemoryStorage结构体的ApplySnapshot将快照数据保存到持久化数据内存映像中。
6、(图中未给出)调用Raft库的Advance接口通知raft库传递过来的Ready结构体数据已经操作完毕,这时候对应的,raft库就会把第二步中保存到未持久化数据缓存的快照数据给删除了。
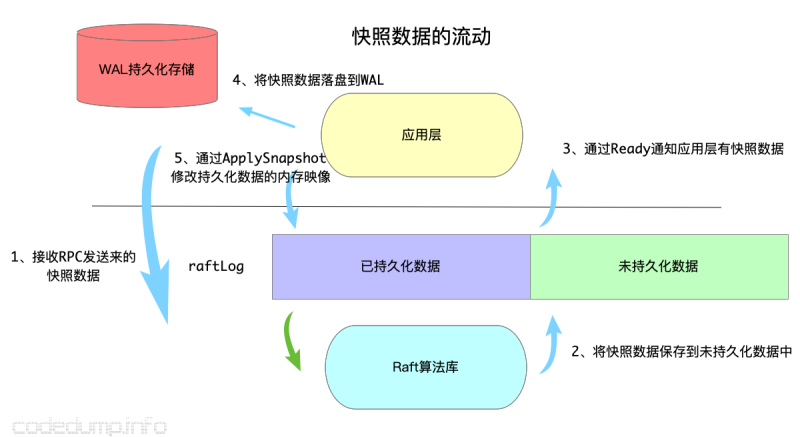
以上是快照数据的流动过程,在节点N接收并持久化快照数据后,后面就可以接收正常的日志了,日志数据的流动过程跟快照数据实际是差不多的,就不再阐述了。
从上面的流程中也可以看出,应用层也就是etcdserver的持久化数据,只有wal日志而已,情况确实是这样的,其接口和实现如下:
type Storage interface {
// Save function saves ents and state to the underlying stable storage.
// Save MUST block until st and ents are on stable storage.
Save(st raftpb.HardState, ents []raftpb.Entry) error
// SaveSnap function saves snapshot to the underlying stable storage.
SaveSnap(snap raftpb.Snapshot) error
// DBFilePath returns the file path of database snapshot saved with given
// id.
DBFilePath(id uint64) (string, error)
// Close closes the Storage and performs finalization.
Close() error
}
type storage struct {
*wal.WAL
*snap.Snapshotter
}
Storage接口是etcdserver持久化数据的接口,其保存的数据有两个接口:
- Save(st raftpb.HardState, ents []raftpb.Entry) error:保存日志数据。
- SaveSnap(snap raftpb.Snapshot) error:保存快照数据。
而Storage接口由下面的storage结构体来实现,其又分为两部分:
- wal:用于实现WAL日志的读写。
- snap:用于实现快照数据的读写。
这里就不展开讨论了。
节点进度的管理
前面提到过,一致性算法与TCP之类的协议,本质上都需要管理未确认数据的缓冲区,但是不同的是,参与一致性算法确认的成员,不会像一般的点对点通信协议那样只有两个,在raft算法中,leader节点除了要维护未持久化缓冲区之外,还需要维护一个数据结构,用于保存集群中其他节点的进度,这部分数据在etcd raft中保存在结构体Progress中,我将我之前阅读过程中加上的注释一并贴出来:
// 该数据结构用于在leader中保存每个follower的状态信息,leader将根据这些信息决定发送给节点的日志
// Progress represents a follower’s progress in the view of the leader. Leader maintains
// progresses of all followers, and sends entries to the follower based on its progress.
type Progress struct {
// Next保存的是下一次leader发送append消息时传送过来的日志索引
// 当选举出新的leader时,首先初始化Next为该leader最后一条日志+1
// 如果向该节点append日志失败,则递减Next回退日志,一直回退到索引匹配为止
// Match保存在该节点上保存的日志的最大索引,初始化为0
// 正常情况下,Next = Match + 1
// 以下情况下不是上面这种情况:
// 1. 切换到Probe状态时,如果上一个状态是Snapshot状态,即正在接收快照,那么Next = max(pr.Match+1, pendingSnapshot+1)
// 2. 当该follower不在Replicate状态时,说明不是正常的接收副本状态。
// 此时当leader与follower同步leader上的日志时,可能出现覆盖的情况,即此时follower上面假设Match为3,但是索引为3的数据会被
// leader覆盖,此时Next指针可能会一直回溯到与leader上日志匹配的位置,再开始正常同步日志,此时也会出现Next != Match + 1的情况出现
Match, Next uint64
// State defines how the leader should interact with the follower.
//
// When in ProgressStateProbe, leader sends at most one replication message
// per heartbeat interval. It also probes actual progress of the follower.
//
// When in ProgressStateReplicate, leader optimistically increases next
// to the latest entry sent after sending replication message. This is
// an optimized state for fast replicating log entries to the follower.
//
// When in ProgressStateSnapshot, leader should have sent out snapshot
// before and stops sending any replication message.
// ProgressStateProbe:在每次heartbeat消息间隔期最多发一条同步日志消息给该节点
// ProgressStateReplicate:正常的接受副本数据状态。当处于该状态时,leader在发送副本消息之后,
// 就修改该节点的next索引为发送消息的最大索引+1
// ProgressStateSnapshot:接收副本状态
State ProgressStateType
// Paused is used in ProgressStateProbe.
// When Paused is true, raft should pause sending replication message to this peer.
// 在状态切换到Probe状态以后,该follower就标记为Paused,此时将暂停同步日志到该节点
Paused bool
// PendingSnapshot is used in ProgressStateSnapshot.
// If there is a pending snapshot, the pendingSnapshot will be set to the
// index of the snapshot. If pendingSnapshot is set, the replication process of
// this Progress will be paused. raft will not resend snapshot until the pending one
// is reported to be failed.
// 如果向该节点发送快照消息,PendingSnapshot用于保存快照消息的索引
// 当PendingSnapshot不为0时,该节点也被标记为暂停状态。
// raft只有在这个正在进行中的快照同步失败以后,才会重传快照消息
PendingSnapshot uint64
// RecentActive is true if the progress is recently active. Receiving any messages
// from the corresponding follower indicates the progress is active.
// RecentActive can be reset to false after an election timeout.
RecentActive bool
// inflights is a sliding window for the inflight messages.
// Each inflight message contains one or more log entries.
// The max number of entries per message is defined in raft config as MaxSizePerMsg.
// Thus inflight effectively limits both the number of inflight messages
// and the bandwidth each Progress can use.
// When inflights is full, no more message should be sent.
// When a leader sends out a message, the index of the last
// entry should be added to inflights. The index MUST be added
// into inflights in order.
// When a leader receives a reply, the previous inflights should
// be freed by calling inflights.freeTo with the index of the last
// received entry.
// 用于实现滑动窗口,用来做流量控制
ins *inflights
}
总结来说,Progress结构体做的工作:
- 维护follower节点的match、next索引,以便知道下一次从哪里开始同步数据。
- 维护着follower节点当前的状态。
- 同步快照数据的状态。
- 流量控制,避免follower节点超载。
具体的算法细节,就不在这里贴出了。
网络数据的收发以及日志的持久化
网络数据的收发以及日志的持久化,这两部分在etcd raft库中,并不是由raft库来实现,而是通过Ready结构体来通知应用层,由应用层来完成。
总结
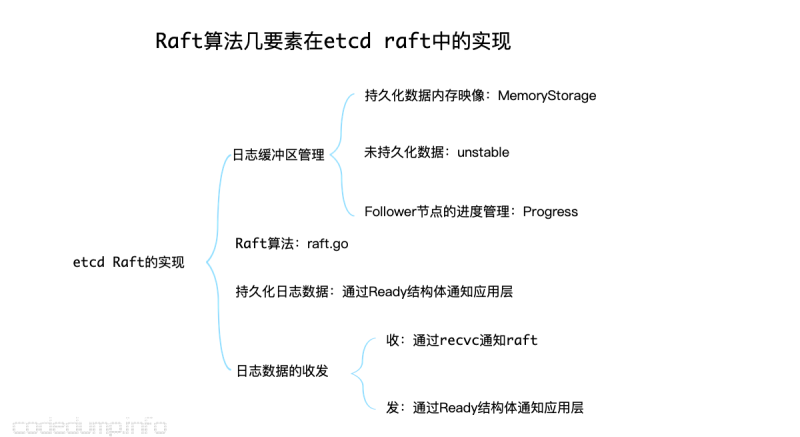
这里将上面的几部分总结如下,有了整体的理解才能更好的了解细节:
 Etcd Raft库的工程化实现 - codedump的网络日志
Etcd Raft库的工程化实现 - codedump的网络日志










 PostgreSQL列存用法 - 墨天轮
PostgreSQL列存用法 - 墨天轮
 PostgreSQL 与 MySQL — 关系数据库管理系统(RDBMS)之间的区别 — AWS
PostgreSQL 与 MySQL — 关系数据库管理系统(RDBMS)之间的区别 — AWS